Open-Source AI Agents in 2026: How to Pick, Host, and Run Production Workflows
The AI agent ecosystem in 2026: models, orchestrators, and tools forming a production-ready stack.
AI agents are no longer research demos. Over the past 12 months, the open-source ecosystem has matured dramatically: orchestrators now handle complex multi-step reasoning, connector ecosystems bridge LLMs to real-world tools, and lighter model options make it realistic for engineering teams to run agent-driven workflows in production without breaking the bank.
This article walks through how to pick an agent framework, the recommended stack (model + orchestration + tooling), cost trade-offs, and a non-negotiable safety checklist for shipping agents responsibly.
Why Now? The State of Play
The convergence of three trends makes 2026 the year AI agents go mainstream in engineering teams:
- Frontier model improvements: Claude Opus 4.6, GPT-5, Gemini 3.x, and Llama 4 have dramatically improved at reasoning, code generation, and tool use. Public trackers (LLM-Stats, WhatLLM) show a new major release almost weekly.
- Agent framework explosion: Community-maintained lists now catalog dozens of open-source agent projects spanning orchestration-first frameworks, developer SDKs, and low-code platforms.
- Cloud GPU pricing war: Competition between AWS, Lambda Labs, and others has driven down inference costs. Spot offerings and per-second billing make running models cheaper than ever.
The net result: teams can evaluate three viable architectures today — hosted API-first, self-hosted LLMs for inference, and hybrid setups that mix both.
Key Takeaways (TL;DR)
- Pick the right framework: if you need many tool connectors, choose an orchestration-first framework; if you need custom state and heavy control, pick a developer-first SDK.
- Model choice matters: use an efficient quantized model for on-prem inference; use cloud APIs for occasional heavy reasoning tasks.
- Plan for safety: sandbox tool execution, redact secrets, log decisions, and run human-in-the-loop gating on dangerous actions.
What to Evaluate When Picking a Framework
Agent frameworks vary across several axes. Use this checklist to evaluate candidates quickly:
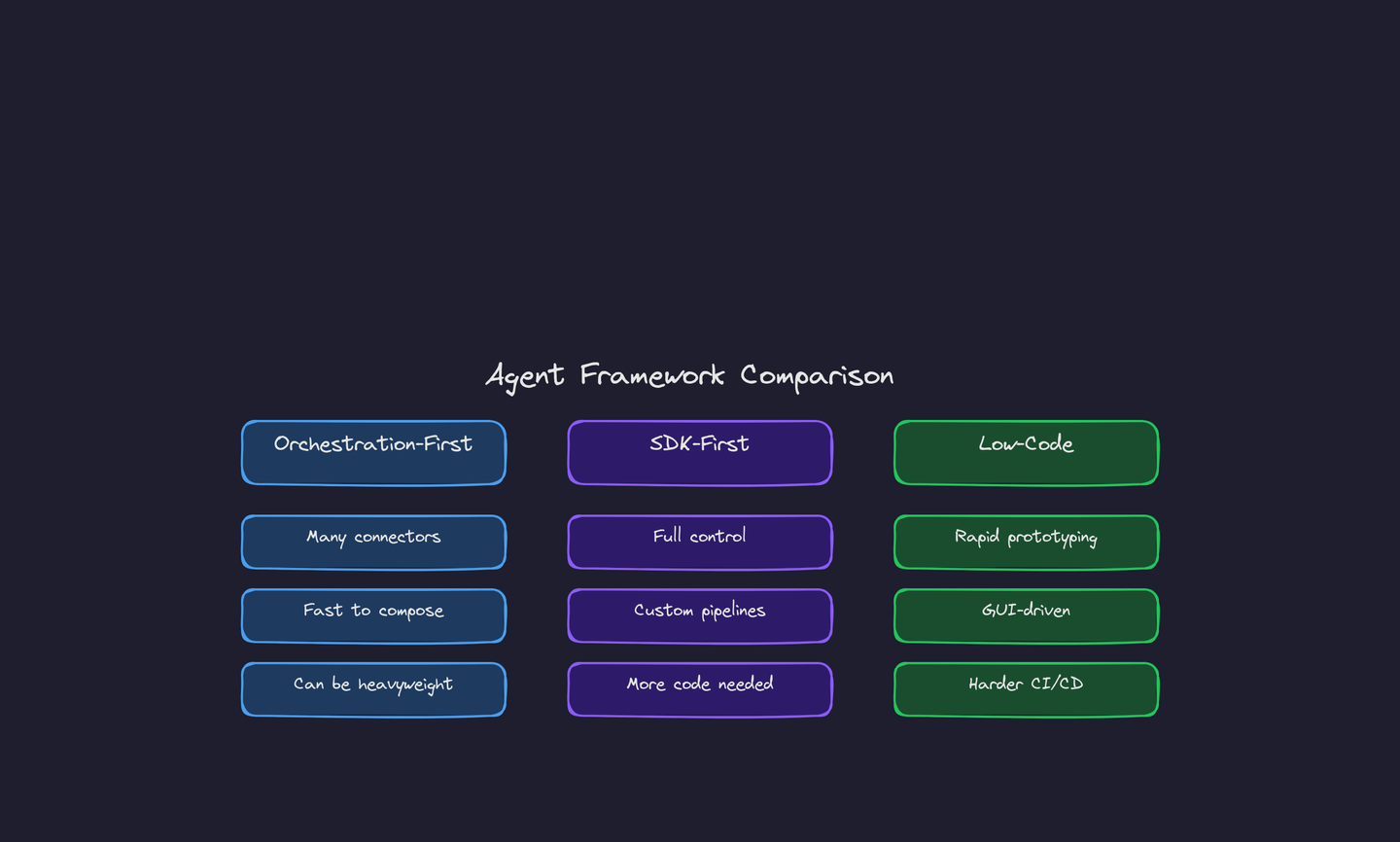
Three dominant archetypes: orchestration-first, SDK-first, and low-code — each with distinct trade-offs.
- Orchestration model: central planner (one controller) vs distributed workers
- Tooling ecosystem: built-in connectors for web, database, browser automation, and shell
- State model: ephemeral vs persistent memory, and how state is stored and retrieved
- Safety primitives: sandboxing, allow-list/deny-list, rate limits, and audit logs
- Extensibility: how easy is it to add a new tool, plugin, or a custom execution environment
- Licensing and community: permissive license and active maintenance matter for production use
Framework Archetypes
- Orchestration-first: focused on routing tasks to tools with built-in connector libraries. Fast to compose, but sometimes heavyweight and harder to customize.
- SDK-first: minimal core that lets developers implement exact control flows. Better for bespoke pipelines and strong privacy constraints, but requires more code.
- Low-code agents: GUI-driven platforms for rapid prototyping. Great for product teams, but often harder to integrate into CI/CD pipelines.
The Recommended Production Stack
Based on community adoption patterns and production deployments, here's a stack that balances cost, reliability, and ease of integration:
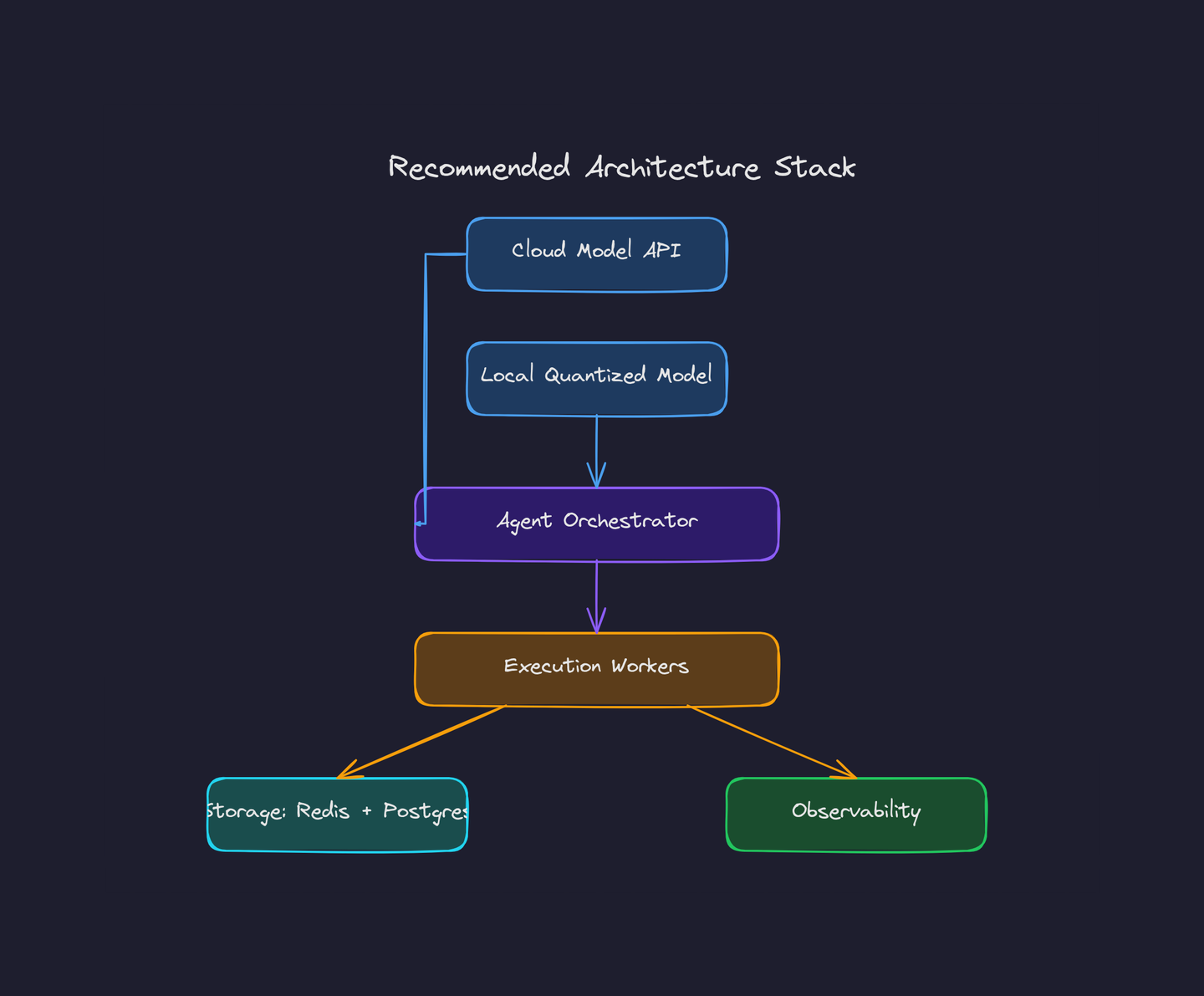
A hybrid model strategy with cloud APIs for heavy reasoning and local quantized models for high-volume inference.
- Model layer: Use an API-first large model (Claude, GPT-5) for high-recall tasks that need deep reasoning. Use a quantized local model (Llama-family) for deterministic, lower-cost inference where latency and privacy matter.
- Agent orchestrator: pick a framework with the connectors you need. Run the orchestrator as a managed service in a container for resilience and easy restarts.
- Execution workers: sandboxed containers (gVisor or Firecracker) or Kubernetes pods with tight IAM policies for tool-side effects.
- Storage & state: Redis for ephemeral state, Postgres for long-term memory and audit logs.
- Observability: structured logs for decisions, metrics for action counts, and a playbook for human review flows.
Cost Considerations
Costs break down into model pricing (API or on-prem GPUs), compute for workers, storage, and developer time. A few practical rules:
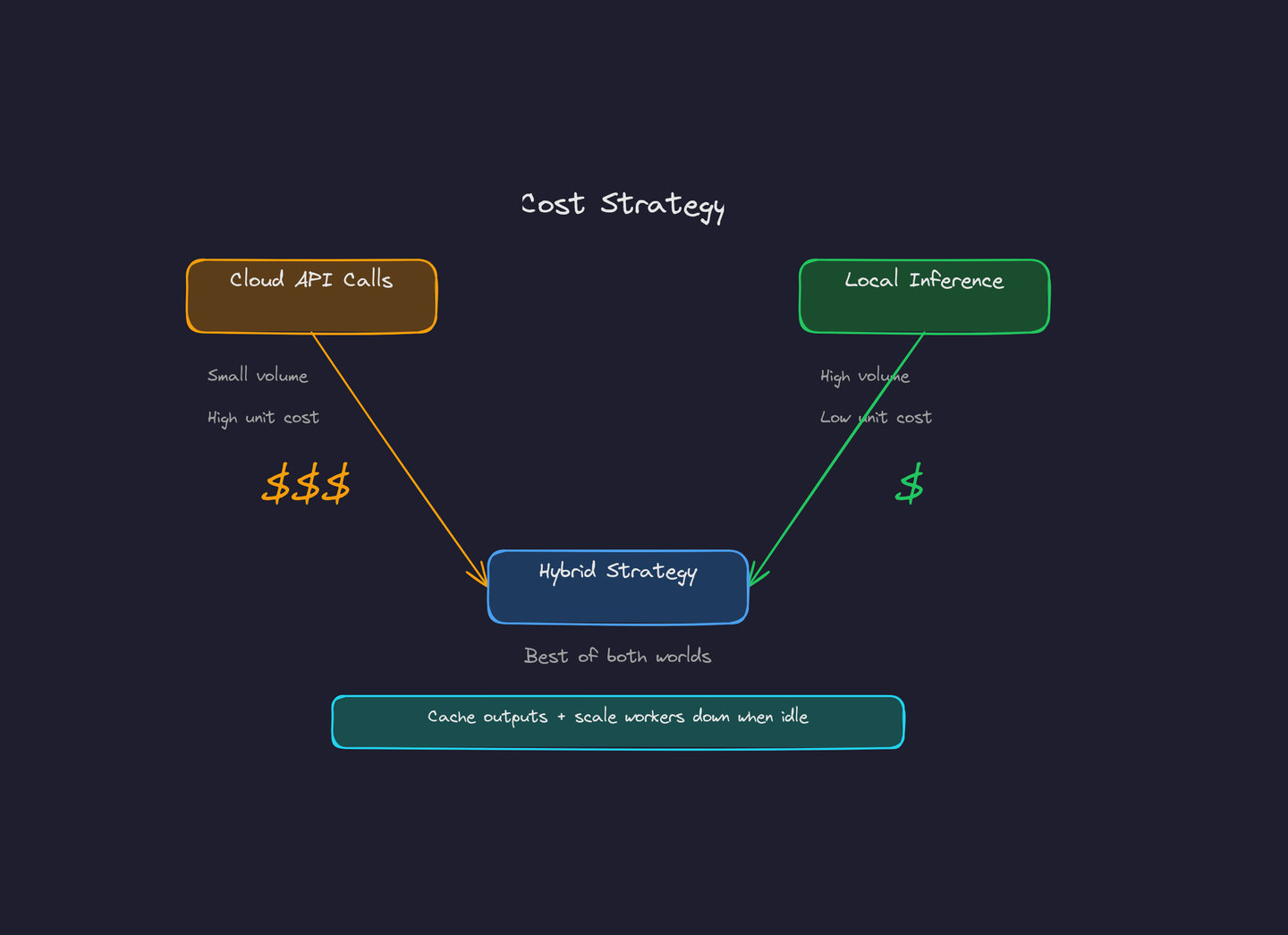
Cloud API calls for rare heavy reasoning vs local quantized inference for high-volume tasks — and why a hybrid approach wins.
- Go hybrid: use cloud APIs for a small fraction of heavy reasoning calls and local quantized models for high-volume cheap inference. This is where most teams see the biggest savings.
- Batch and cache: cache model outputs for repeated queries and batch low-priority jobs to reduce peak spend.
- Autoscale workers: spiky workloads are cheaper if workers scale down during idle periods — don't pay for containers you're not using.
Before finalizing a cost plan, verify pricing on official vendor pages — cloud GPU, API, and storage prices change frequently. What was cheap last quarter may not be cheap today.
Safety Checklist (Non-Negotiable)
Agents with tool access are high-risk by design. When your AI agent can run shell commands, control your browser, and manage your messaging tokens, any vulnerability becomes catastrophic. Use this checklist before enabling any external action:

Five non-negotiable safety measures before any agent touches production systems.
- Sandbox execution: run unknown code in least-privileged containers with no network access to internal services unless explicitly required
- Secrets redaction: prevent models from seeing raw credentials. Redact API keys, tokens, and passwords before they enter the prompt or logging pipeline
- Human gating: require manual approval for destructive actions — file deletions, financial transactions, production deployments
- Audit trails: log every prompt, tool call, and decision rationale. You will need this for post-mortems and compliance
- Rate limiting & quotas: guard against runaway loops, infinite tool calls, and cost spikes from malformed prompts
Quick Example: Agent Pipeline
Here's what a basic orchestration flow looks like in practice:
// Pseudocode — orchestration flow
const planner = new AgentPlanner({ model: cloudModel });
if (request.requiresSensitiveAction) {
await planner.requestHumanApproval();
} else {
const task = planner.plan(request);
const result = await worker.runTool(task.tool, task.args);
planner.integrate(result);
return planner.finalizeResponse();
}The pattern is simple: plan, gate, execute, integrate. The complexity comes from making each step robust — handling timeouts, malformed tool outputs, and permission failures gracefully.
Lessons Learned from Early Adopters
Teams that shipped agents in 2025 learned these lessons the hard way:
- Start with small scope: pick 1-2 high-value automated tasks (data enrichment, ticket triage, alert routing), not full autonomous agents. Prove value before expanding.
- Measure action outcomes: automate only where you can measure precision and recall. If you can't tell whether the agent did the right thing, you shouldn't have it acting autonomously.
- Design for observability from day one: you will need to debug both LLM failures (hallucinations, wrong tool selection) and connector failures (API timeouts, auth expirations). Build logging in first, not last.
- Self-hosted does not mean safe: running locally protects data privacy, but does not protect against prompt injection, skill-based attacks, or privilege escalation. Security boundaries matter more than deployment location.
What's Next
Expect more composable tool standards (open connector specs) and stronger model-efficiency trade-offs that make local inference even cheaper. The model landscape is evolving weekly — watch the official model cards and vendor pricing pages to plan migration windows.
The teams that win with agents won't be the ones with the biggest models. They'll be the ones with the safest, most observable, and most cost-effective pipelines.
Further Reading
- LLM-Stats — model release tracker
- WhatLLM — April 2026 model roundup
- Awesome AI Agents 2026 (community list)
- ComputePrices — GPU cloud pricing comparison
Tags: #AI #AIAgents #GenAI #MLOps #SelfHosted #DevOps #OpenSource