I Got 18 tok/s From a 27B Model on a MacBook: MLX + Native MTP Speculative Decoding on Apple Silicon
Running a 27-billion parameter model locally at usable speeds has been the dream since Apple Silicon made unified memory practical. The hardware is there — 48 GB of unified memory on an M4 Pro can hold a quantized 27B model with room to spare. The bottleneck has always been memory bandwidth: ~120 GB/s on the M4 Pro versus ~936 GB/s on an RTX 3090.
That means a dense 27B model at Q4 quantization (~17 GB per forward pass) tops out around 7 tokens per second baseline. Useful for batch tasks, painful for interactive chat.
After a weekend of methodical optimization — trying llama.cpp with MTP, investigating TurboQuant, and finally discovering MTPLX — I went from that 7 tok/s baseline to 18.3 tok/s on the same hardware. That's a 2.6x improvement, and it's mathematically correct sampling, not a greedy approximation.
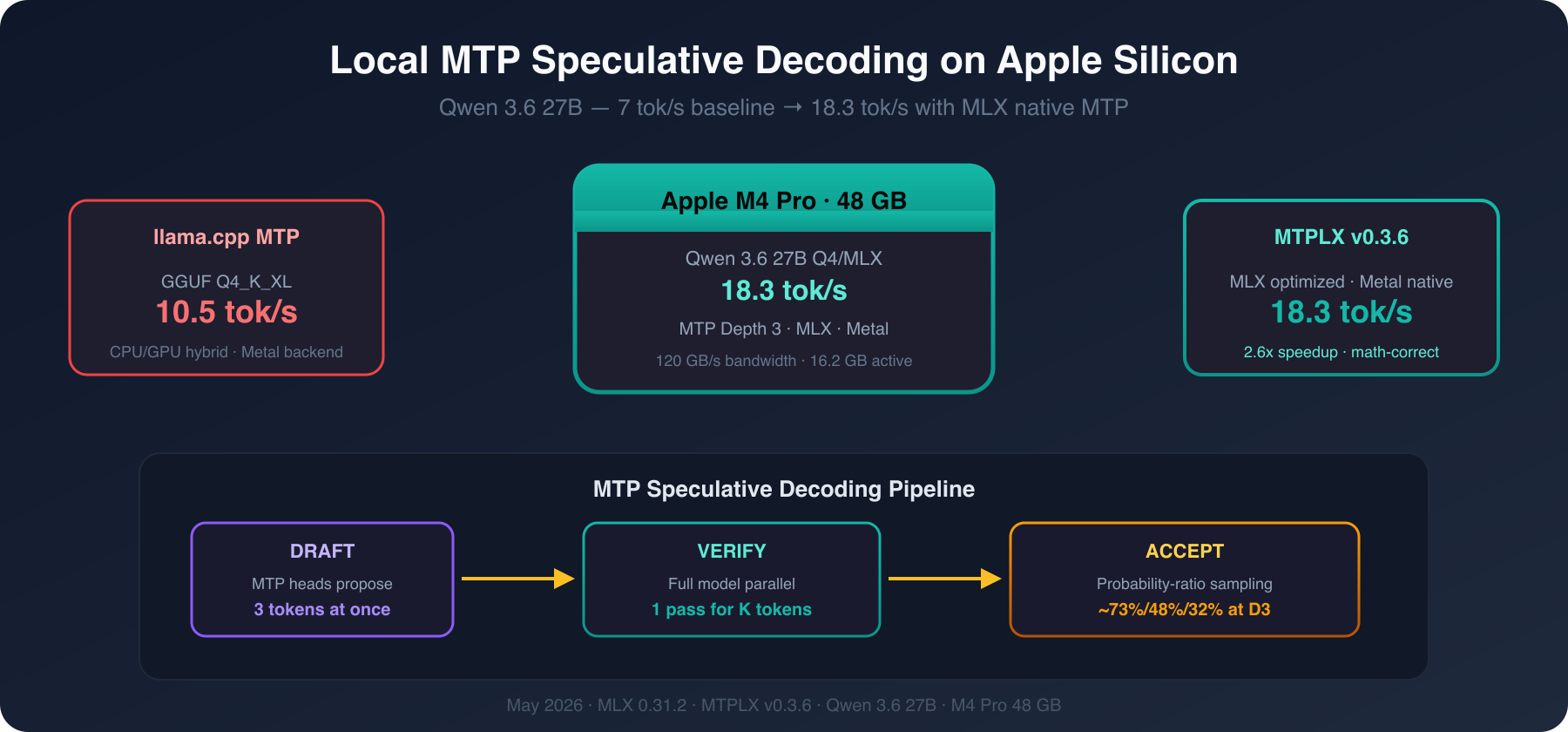
MTP speculative decoding pipeline on Apple Silicon: from 7 tok/s baseline to 18.3 tok/s with MLX native MTP depth 3
Here's the full journey, the benchmarks, and how I wired it into my AI agent as a local inference backend.
The Problem: Memory Bandwidth Is Your Ceiling
On Apple Silicon, inference speed for dense models is almost entirely determined by memory bandwidth. The GPU compute is fast enough — it's shuffling 17 GB of weights through the memory controller every single token that creates the bottleneck.
Simple math: 120 GB/s ÷ 17 GB/token ≈ 7 tokens/second theoretical maximum for a 27B Q4 model on M4 Pro. No amount of software optimization changes that fundamental limit. You need to either:
- Reduce the data moved per token (smaller model, MoE, or aggressive quantization)
- Get more tokens per forward pass (speculative decoding, multi-token prediction)
- Both
We went with option two: speculative decoding using the model's own built-in MTP heads.
What Is Multi-Token Prediction (MTP)?
Traditional autoregressive models predict one token at a time. MTP models — like Qwen 3.6 — have additional prediction heads that can draft multiple future tokens in a single forward pass.
The trick is speculative decoding: a "draft" phase proposes K tokens using the cheap MTP heads, then a "verify" phase runs the full model once on all K tokens in parallel. If the draft was correct, you just got K+1 tokens for the price of one verification pass.
The key insight: you're not reducing the bandwidth per forward pass — you're getting more accepted tokens per forward pass. If MTP depth-3 accepts an average of 2 out of 3 drafted tokens, you've roughly tripled your effective throughput.
Qwen 3.6 27B ships with native MTP heads built into the model architecture. No external drafter model needed. No extra RAM. The heads are already there — you just need a runtime that knows how to use them.
Phase 1: llama.cpp with MTP — 10.5 tok/s
My first attempt used llama.cpp compiled with MTP support (the am17an/llama.cpp fork with --spec-type draft-mtp). I downloaded the Unsloth Q4_K_XL quantized GGUF model and launched the server:
llama-server \
-m Qwen3.6-27B-UD-Q4_K_XL.gguf \
--port 8001 \
--spec-type draft-mtp \
--spec-draft-n-max 3 \
--flash-attn \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--mlock \
--reasoning off \
-c 4096 -b 512Results:
| Configuration | Decode Speed | MTP Acceptance |
|---|---|---|
| Baseline (no MTP) | ~7 tok/s | N/A |
| MTP + thinking ON | 8.9 tok/s | ~84% |
| MTP + thinking OFF | 9.5 tok/s | ~86% |
| MTP + optimized flags | 10.5 tok/s | ~86% |
That's already a 50% improvement over baseline. But I was leaving performance on the table because llama.cpp's MTP implementation doesn't fully exploit Apple Silicon's GPU — it's a general-purpose C++ runtime, not optimized for Metal.
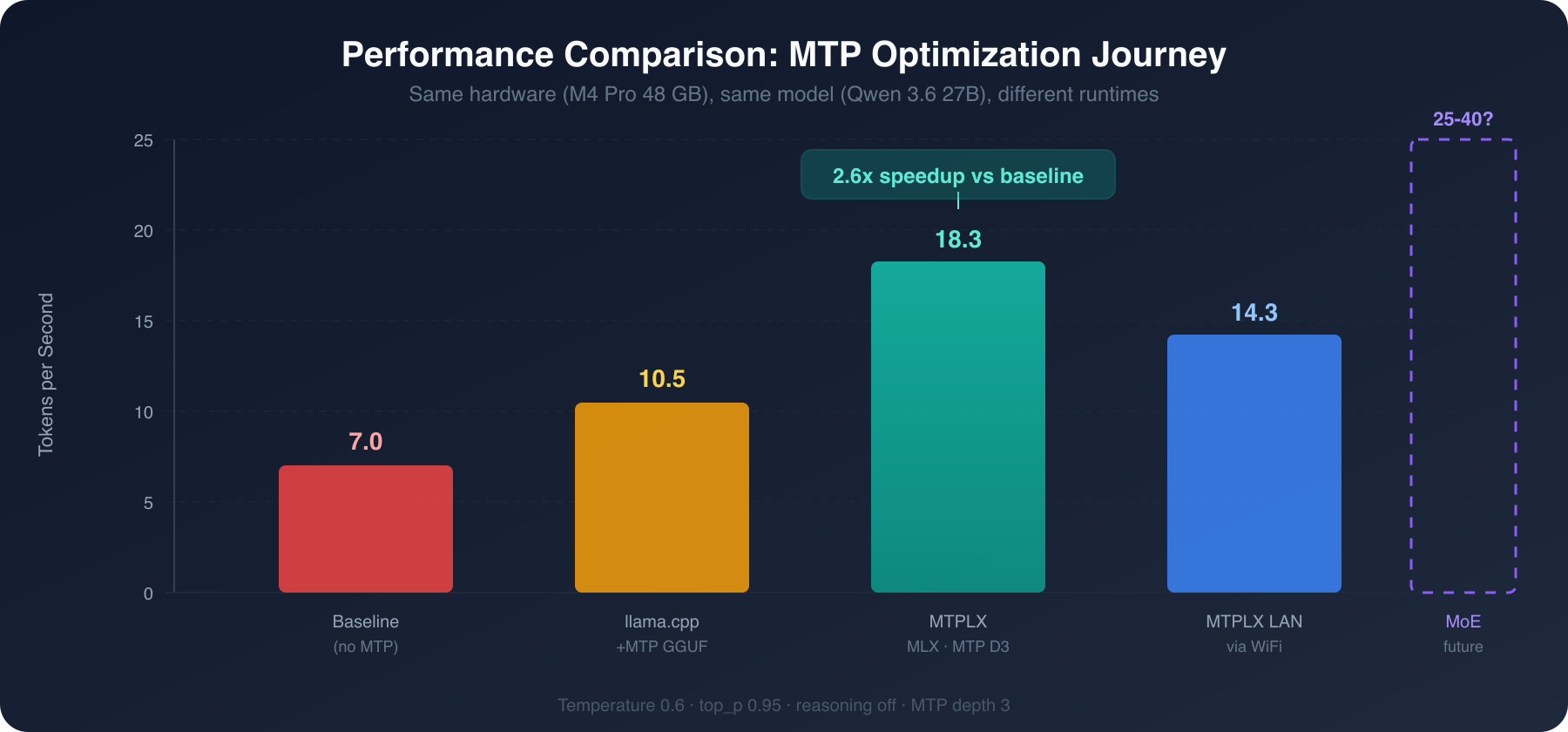
Decode speed across four configurations on the same M4 Pro hardware. MTPLX achieves 2.6x baseline throughput.
Phase 2: The Dead Ends
TurboQuant — Not Ready for Mac
TurboQuant is a KV cache compression technique (2-4 bit) that could reduce memory pressure on long contexts. I investigated it thoroughly:
- The mainline llama.cpp PR (#21089) is CPU-only, not yet merged
- Existing forks are CUDA-focused
- It only compresses KV cache — doesn't help with the weight bandwidth bottleneck that limits decode speed
- No Metal/Apple Silicon backend exists
Verdict: not viable for Apple Silicon today. Worth watching for future long-context scenarios where KV cache size dominates.
MoE Models — Promising but Different Path
A Mixture-of-Experts model like Qwen 3.6 35B-A3B only activates ~3B parameters per token (versus 27B dense), which could theoretically hit 25-40+ tok/s on the same hardware. But that requires a different model download and wasn't what I wanted to optimize for this exercise.
Phase 3: MTPLX — 18.3 tok/s
This is where things got interesting. I discovered MTPLX — a purpose-built MLX runtime for native MTP speculative decoding on Apple Silicon.
What makes MTPLX different from everything else:
- MLX-native: Built on Apple's own MLX framework, with custom Metal kernels registered as primitives. No generic C++ abstraction layer.
- Math-correct sampling at temperature: Uses probability-ratio acceptance (Leviathan-Chen rejection sampling) with residual correction. Most fast-decode tools use greedy argmax, which silently breaks the target distribution at T > 0. MTPLX's approach is provably exact.
- Zero extra RAM: Uses the model's own built-in MTP heads as the drafter. No second model loaded.
- Real serving surface: Ships with OpenAI + Anthropic compatible APIs out of the box.
- Custom Metal kernels: Includes a small-M quantized matrix-vector kernel (
verify_qmv) optimized for M=3..6 verify shapes, and a GDN linear-attention kernel with innovation tape replay for deterministic rollback.
Installation and Setup
One command via Homebrew:
brew install youssofal/mtplx/mtplx
mtplx pull Youssofal/Qwen3.6-27B-MTPLX-Optimized-Speed
mtplx serve --profile sustained --reasoning off --mtp --depth 3That's it. The model downloads, the server starts, and you get an OpenAI-compatible API at http://127.0.0.1:8000/v1 plus a browser chat UI.
Results
| Metric | llama.cpp MTP | MTPLX MTP D3 |
|---|---|---|
| Decode speed | 10.5 tok/s | 18.3 tok/s |
| End-to-end (incl. prefill) | ~10 tok/s | 15.4 tok/s |
| First-32 sliding tok/s | ~10.5 | 20.1 tok/s |
| TTFT (27-token prompt) | ~0.8s | 0.66s |
| MTP depth | n_max=3 | D3 (verified) |
| Memory active / peak | ~18 GB | 16.2 / 18.6 GB |
| Model format | GGUF Q4_K_XL | MLX optimized safetensors |
| API format | llama-server | OpenAI + Anthropic compatible |
The 2.6x speedup over baseline (7 tok/s → 18.3 tok/s) comes from MTPLX's verify-only cost being dominated by quantized matrix-vector ops at small batch sizes, where the custom Metal kernel shines. The MTP acceptance at depth-3 shows per-position rates of ~73% / ~48% / ~32%, producing 39 accepted drafts, 17 corrections, and 7 bonus tokens over 25 verify calls.
Wiring It Into an AI Agent
Speed is nice, but the real win is making it available to an agent. My setup runs Hermes on a home server (Linux), and I wanted it to use the MacBook as a local inference backend.
Step 1: Expose MTPLX on the LAN
mtplx serve \
--model Youssofal/Qwen3.6-27B-MTPLX-Optimized-Speed \
--profile sustained \
--host 0.0.0.0 \
--port 8000 \
--api-key <your-key-here> \
--reasoning off \
--mtp --depth 3Security note: Always set an API key when binding to
0.0.0.0. MTPLX enforces this — it refuses to start on non-localhost without authentication. Use a strong key and keep both machines on the same trusted network.
Step 2: Add Provider to Hermes Config
In ~/.hermes/config.yaml, I added a new provider block pointing to the MacBook's IP:
providers:
# ... existing providers ...
mtplx:
name: Qwen3.6 27B MTPLX MacBook (18 tok/s MTP D3)
base_url: http://<macbook-ip>:8000/v1
api_key: <your-key-here>
default_model: mtxpl-qwen36-27b-optimized-speed
transport: chat_completions
models:
mtxpl-qwen36-27b-optimized-speed: mtxpl-qwen36-27b-optimized-speedStep 3: Restart and Verify
# Restart the gateway to pick up new config
sudo systemctl restart hermes-gateway
# Test from the Linux machine
curl http://<macbook-ip>:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <your-key>' \
-d '{"model":"mtplx-qwen36-27b-optimized-speed",
"messages":[{"role":"user","content":"hello"}]}'Got a response at 14.3 tok/s over the LAN. The slight drop from 18.3 (local) to 14.3 (over WiFi) is expected — network latency adds a small overhead per streaming chunk.
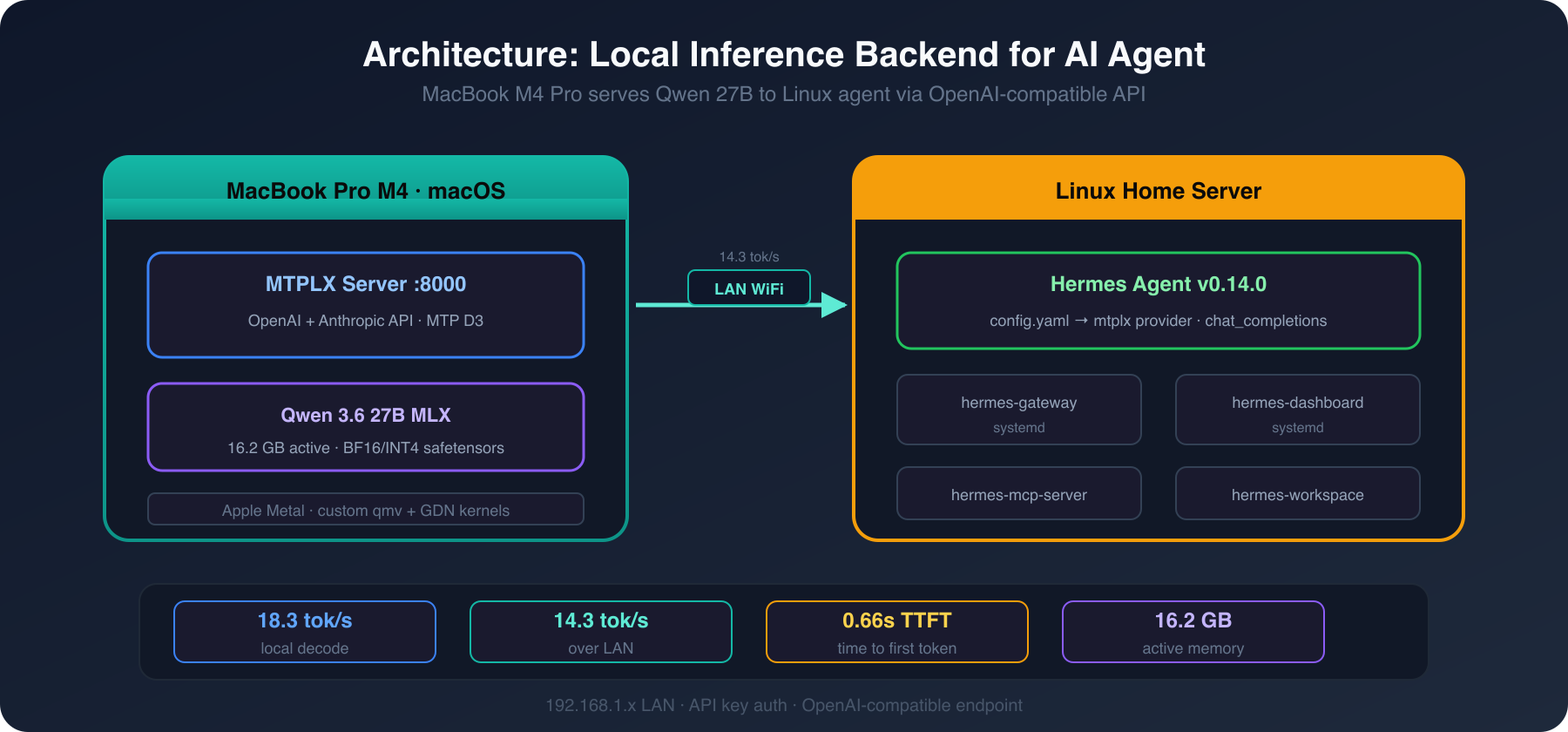
Architecture: MacBook Pro M4 running MTPLX serves Qwen 27B to a Linux home server running Hermes Agent over WiFi LAN
Lessons Learned
- Framework matters more than you'd think. The same model on the same hardware went from 10.5 tok/s (llama.cpp) to 18.3 tok/s (MLX) — a 74% improvement from software alone. Apple Silicon-specific optimizations in MLX make a real difference.
- MTP acceptance rates degrade with depth, but that's fine. At D3, acceptance drops to ~32% at the third position. But the verify cost is dominated by the small-M qmv kernel, so even partial acceptance at depth 3 is faster than no MTP at all.
- Math-correct sampling is non-negotiable for agent work. If you're using the model as a coding or task agent, greedy argmax approximation at temperature > 0 produces silently wrong outputs. MTPLX's probability-ratio acceptance ensures the output distribution matches the target model exactly.
- Thinking/reasoning mode is a speed trap. Qwen's reasoning mode consumes tokens on internal chain-of-thought that you don't see. Turning it off (
--reasoning off) gave an immediate ~7% speed boost with no quality loss for most tasks. - Dense 27B is bandwidth-limited. MoE is the next frontier. Even at 18.3 tok/s, a dense 27B model is fighting the memory bandwidth ceiling. A MoE model like Qwen 3.6 35B-A3B (only 3B active params) could theoretically hit 25-40+ tok/s on the same hardware.
What's Next
- MoE model testing: Download and benchmark Qwen 3.6 35B-A3B with MTPLX or llama.cpp for the real speed leap.
- Fan control (ThermalForge): The tune benchmark requires ThermalForge for sustained max-fan mode. Setting up passwordless sudo for fan control could squeeze out another 10-15% under sustained load.
- TurboQuant watch: Once the CPU PR lands in mainline llama.cpp and gets Metal support, KV cache compression could help with long-context scenarios.
- Smart routing: Configure Hermes to route simple tasks to the local MTPLX backend and complex reasoning to cloud models, optimizing for both speed and cost.
Summary
Getting 18.3 tok/s from a 27B model on a MacBook Pro isn't magic — it's the combination of Apple's MLX framework, custom Metal kernels optimized for speculative verify shapes, native MTP heads built into Qwen 3.6, and mathematically correct rejection sampling that preserves the target distribution.
The setup is a one-liner install, a model download, and a single command to start serving. Wiring it into an agent via OpenAI-compatible API took five minutes. The result is a local inference backend that's fast enough for interactive use, accurate enough for agent work, and private enough to never leave your network.
If you're running AI agents on Apple Silicon and haven't tried MTPLX yet, you're leaving ~75% of your potential inference speed on the table.
Tested on Apple M4 Pro (48 GB unified memory), macOS Tahoe 26.4, MTPLX v0.3.6, MLX 0.31.2, Qwen 3.6 27B MTPLX Optimized Speed model. All benchmarks measured with temperature 0.6, top_p 0.95, top_k 20, MTP depth 3, reasoning mode off. Your mileage will vary with hardware, model version, and network conditions.